![[Amazon Bedrock] RAG利用時の選択肢「Kendra」と「Bedrock Knowledge Bases」を比較する](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-e3065182082062711612153bbdcf1d96/c04359de689df2f56eb066576ab63fb5/amazon-bedrock)
[Amazon Bedrock] RAG利用時の選択肢「Kendra」と「Bedrock Knowledge Bases」を比較する

みなさん、こんにちは!
福岡オフィスの青柳です。
Amazon Bedrockで「RAG」を実現しようとした場合、Bedrockと組み合わせるものとして以下のパターンが考えられます。
- Amazon Kendraを使う
- Amazon Bedrock Knowledge Basesを使う
- 上記以外の方法
- LangChainなどのライブラリを使う
- 独自に実装する
これらのうち、よく使われているのは「Kendra」と「Bedrock Knowledge Bases」ではないでしょうか。
特に、Bedrockのリリース (GA) 時点では「Bedrock Knowledge Bases」がまだ存在しなかったため、Kendraを使うことがほとんどだったのではないかと思います。
しかし、Bedrock Knowledge Basesの登場後は「KendraとBedrock Knowledge Bases、どちらを使うのが良いのか?」と悩む場面も出てきているのではないでしょうか。
このように悩ましい「Kendra」と「KendraとBedrock Knowledge Bases」の選択の手助けとして、両者の違いを比較して整理してみることにしました。
概要
「Amazon Kendra」 (以後「Kendra」と表記)
Bedrockの登場前から存在する、独立した「エンタープライズ検索」サービスです。
検索処理の方式について、詳細には公開されていませんが「自然言語処理と高度な機械学習アルゴリズムを使用」と謳われており、従来のキーワードベースの検索サービスではなくセマンティック (意味) ベースの検索サービスを提供します。
サービスを構成する要素 (ベクトルストア、データソースクローラー、検索エンジン、など) が全て内包されている「オールインワン」型のサービスであるのが特徴です。
「Amazon Bedrock Knowledge Bases」 (以後「Bedrock Knowledge Bases」と表記)
※ 以前は「Knowledge Bases for Amazon Bedrock」という名称でしたが、2024年9月頃に現在の名称に変わりました。
Bedrockの一機能であり、RAGを実現するための「検索機能」の位置付けです。
検索インデックスの作成時、および、作成されたインデックスの検索時に生成AI (Bedrock) の組み込み (Embedded) モデルを使用しており、検索ワードに完全一致ではなく「意味的に近い」データを検索することができます。
RAGの「検索」(Retrieve) 部分だけではなく「検索結果からの回答生成」(Retrieval-Argumented Generation) を一気通貫で実行するAPIを提供します。
ベクトルストア
● Kendra
サービスに内包されており、ベクトルストアの種類を選択することはできません。
● Bedrock Knowledge Bases
以下のベクトルストアを選択可能です。
- Amazon OpenSearch Serverless
- Amazon Aurora (PostgreSQL)
- サードパーティ製品
- MongoDB Atlas
- Pinecone
- Redis Enterprise Cloud
※ OpenSearch Serverlessの選択時に限りKendraのウィザード画面から自動作成可能、他のベクトルストアは事前作成が必要です。
KendraとBedrock Knowledge Basesにおけるベクトルストアの扱いの違いを分かり易く図にすると、このようになります。
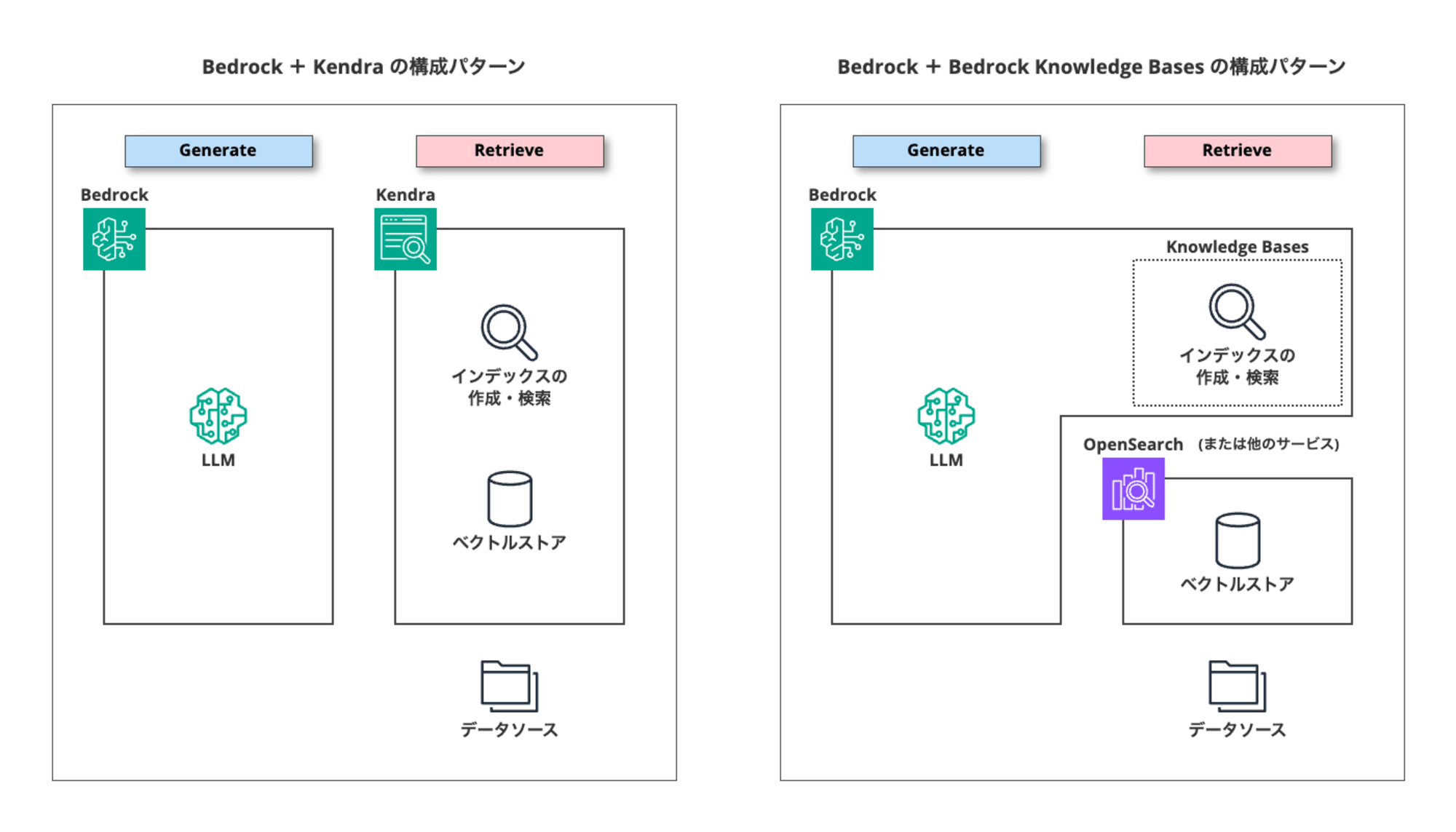
データソース
対応するデータソースの種類
● Kendra
30種類以上のデータソースに対応しています。
※ 対応するデータソースの種類の一覧はAWS公式ドキュメントを参照してください。
● Bedrock Knowledge Bases
以下のデータソースに対応しています。
- Amazon S3
- Atlassian Confluence (プレビュー)
- Microsoft SharePoint (プレビュー)
- Salesforce (プレビュー)
- Webクローラー (プレビュー)
対応するデータファイルの形式
● Kendra / Bedrock Knowledge Bases
| データファイル形式 | Kendra | Bedrock Knowledge Bases |
|---|---|---|
| プレーンテキスト (.txt) | 対応 | 対応 |
| カンマ区切りテキスト (.csv) | 対応 | 対応 |
| Markdown (.md) | 対応 | 対応 |
| HTML (.html) | 対応 | 対応 |
| XML (.xml) | 対応 | ー |
| XSL変換 (.xslt) | 対応 | ー |
| JSON (.json) | 対応 | ー |
| リッチテキスト形式 (.rtf) | 対応 | ー |
| Microsoft Word (.doc/.docx) | 対応 | 対応 |
| Microsoft Excel (.xls/.xlsx) | 対応 | 対応 |
| Microsoft PowerPoint (.ppt/.pptx) | 対応 | ー |
| PDF (.pdf) | 対応 | 対応 |
※ Bedrock Knowledge Basesでは、後述する「高度な解析オプション」を利用する場合には「PDF形式」のみがサポートされます。
対応するデータファイルのサイズ
● Kendra / Bedrock Knowledge Bases
共に「最大 50 MB」です。
データソースの同期
● Kendra
「手動」「自動 (スケジュール実行)」が選択可能です。
Bedrock Knowledge Bases
標準機能では「手動」のみ可能です。
EventBridge Schedulerと組み合わせることで、スケジュールによる自動実行が可能です。
使用するモデル
埋め込みモデル (インデックス作成/インデックス検索)
● Kendra
(処理方式として、インデックス作成/インデックス検索に生成AIを使用しないため、本項目は該当しません)
● Bedrock Knowledge Bases
Bedrockで利用可能な埋め込みモデルを選択して使用します。
- Amazon Titan Embeddings G1 - Text (※)
- Amazon Titan Text Embeddings V2
- Cohere Embed English
- Cohere Embed Multilingual
※ 以前に作成済みのベクトルストアでのみ利用可能であり、新規に利用することはできません。
回答生成で使用するモデル
● Kendra
Kendra自体には回答生成の機能は無く、組み合わせるLLMは自由です。
● Bedrock Knowledge Bases
ナレッジベースの検索のみを行う「Retrieve API」と、検索結果を用いて回答生成まで行う「RetrieveAndGenerate API」が用意されており、それぞれで使用できるモデルが異なります。
前者 (Retrieve API) の場合、回答生成はBedrock Knowledge Basesに依存しないため、Bedrockで利用可能な任意のモデルを使用できます。
後者 (RetrieveAndGenerate API) の場合、用意されたモデルから選択する必要があります。(以下の通り)
※ 2024/11/25更新: サポートされるモデルが記事初出時より大幅に増えていましたので、最新化しました。
- AI21 Labs
- Jamba 1.5 Mini
- Jamba 1.5 Large
- Jamba-Instruct
- Amazon
- Titan Text G1 - Premier
- Anthropic
- Claude 3.5 Haiku
- Claude 3.5 Sonnet v2
- Claude 3.5 Sonnet
- Claude 3 Haiku
- Claude 3 Sonnet
- Claude 2.1
- Claude 2
- Cohere
- Command R+
- Command R
- Meta
- Llama 3.2 11B Instruct
- Llama 3.2 90B Instruct
- Llama 3.1 405B Instruct
- Llama 3.1 70B Instruct
- Llama 3.1 8B Instruct
- Llama 3 70B Instruct
- Llama 3 8B Instruct
- Mistral AI
- Mistral Large (24.07)
- Mistral Large (24.02)
- Mistral Small (24.02)
チャンキング
● Kendra
チャンキングに関する設定可能なパラメーターは存在せず、自動的に適切なチャンク分割が行われます。
● Bedrock Knowledge Bases
以下のチャンク分割オプションが選択可能です。
- デフォルトチャンキング: 自動的にチャンクサイズを調整
- 固定サイズのチャンキング: チャンクサイズを指定
- 階層的チャンキング: 「検索時」と「回答生成時」で別々のチャンクサイズを採用
- セマンティックチャンキング: 自然言語処理によって意味のある区切りでチャンクを分割
- チャンキングなし: チャンク分割をせず、1ファイルが1チャンクとなる (ドキュメントの前処理と組み合わせる想定)
Advanced RAG
● Bedrock Knowledge Bases のみ
2024年7月のBedrock Knowledge Basesのアップデートにより、「Advanced RAG」を実現する複数の機能が追加されました。
Advanced RAGとは、従来のRAG (「Naive RAG」とも呼ばれる) の精度を高めるために考案された、より高度なRAG手法を指します。(Bedrock特有の機能ではなく、生成AIの一般的な概念です)
高度な解析オプション
データソースがPDFファイルなどの「表」や「図」を含む形式の場合、従来のRAGでは表や図に書かれているテキストを識別することができず、これらの内容はインデックス化の対象外となっていました。
高度な解析 (Advanced Parsing) オプションによって、基礎モデル (Claude 3 Sonnet、Claude 3 Haiku) を用いてPDFファイル等に含まれる表や図などを解析して、テキストを取り込むことが可能になります。
チャンキング戦略の追加
より高度なチャンキング戦略の選択肢として「階層的チャンキング」と「セマンティックチャンキング」が追加されました。
(「チャンキング」項目で説明済み)
カスタムチャンキング
Bedrock Knowledge Basesでは、予め用意されているチャンキング戦略に代えて、Lambda関数を使って独自のチャンキング処理を実行することが可能です。
LangChainやLlamaIndexなどのOSSフレームワークで提供されているものを利用したり、自前で実装することができます。
クエリ分解
従来のRAGでは「Retrieve」の際にユーザーの入力テキストをそのまま使ってインデックスのクエリを行いますが、入力テキストが長文・複雑である場合には意図した検索結果が得られない場合があります。
そこで、入力テキストを適切に分解して複数のクエリを生成することで、検索の精度を高めることができます。
参考情報: Bedrock Knowledge BasesのAdvanced RAGに関する機能についての解説
メタデータによるフィルタリング
● Kendra
メタデータの付与
データソースからインデックスに取り込まれたデータには、標準で「タイトル」「データソースURI」などの属性 (メタデータ) が付与されます。
標準に無いメタデータを付与するには、ファイルとメタデータ情報の対応を記述した「メタデータファイル」(〜.metadata.json) をデータソース内に配置しておき、これを参照するように設定します。
Contents Document Enrichment (CDE)
Kendraでは、CDEを使ってメタデータの生成を自動化することが可能です。
ファイルの属性値が特定の条件に合致する場合に、指定されたタグ (メタデータ) を付与することができます。
例えば「”作成者”が特定のメンバーの場合」「”更新日”が一定の期間に含まれる場合」などの条件によって、タグ付けが可能です。
メタデータを使った検索結果のフィルタリング
インデックスを検索 (Retrieve) する際に、属性の条件を指定して検索結果のフィルタリングを行うことができます。
例えば、以下のようなフィルタリングを行うことができます。
- データソースURIに対してフィルタリングを指定、特定フォルダ階層のデータのみを検索対象にする
- カテゴリを表すカスタムメタデータを付与しておき、特定カテゴリのデータのみを検索対象にする
- 機密情報を表すカスタムメタデータを付与しておき、機密情報に設定されていないデータのみを検索対象にする
参考情報: Kendraにおけるメタデータフィルタリング
● Bedrock Knowledge Bases
メタデータの付与
データソースからインデックスに取り込まれたデータには、標準で「タイトル」「データソースURI」などの属性 (メタデータ) が付与されます。
標準に無いメタデータを付与するには、ファイルとメタデータ情報の対応を記述した「メタデータファイル」(〜.metadata.json) をデータソース内に配置しておき、これを参照するように設定します。
メタデータを使った検索結果のフィルタリング
インデックスを検索 (Retrieve) する際に、属性の条件を指定して検索結果のフィルタリングを行うことができます。
例えば、以下のようなフィルタリングを行うことができます。
- データソースURIに対してフィルタリングを指定、特定フォルダ階層のデータのみを検索対象にする
- カテゴリを表すカスタムメタデータを付与しておき、特定カテゴリのデータのみを検索対象にする
- 機密情報を表すカスタムメタデータを付与しておき、機密情報に設定されていないデータのみを検索対象にする
参考情報: Bedrock Knowledge Basesにおけるメタデータフィルタリング
アクセス権限によるフィルタリング
● Kendra のみ
Kendraでは、データソースに設定されたアクセス権限 (ACL) に基づいて、検索結果をユーザーベースでフィルタリングすることが可能です。
データソースからのACL情報の取り込み
ACL取り込みに対応したデータソースでは、データソースのクロール (同期) 時に自動的にACL情報が取り込まれてインデックスに格納されます。
ただし、以下のような制約があることに留意してください。
- 1つのファイルに設定されたACL情報について、取り込める数に上限があります。(ユーザー・グループ合わせて200エントリまで)
- 取り込まれたACL情報の一覧を確認する方法はありません。(同期ログには記録されるため、対象のファイルを探してどのACL情報が取り込まれたのかを確認することは一応可能です)
検索実行時にユーザーベースで検索結果をフィルタリング
検索実行時に「利用ユーザー情報」をAPI/SDKにパラメーターとして渡すことで、インデックスに取り込まれたACL情報に従って、利用ユーザーがアクセス権限を持つデータのみが検索結果に出力されます。(アクセス権限を持たないデータは検索結果に含まれないようになる)
利用ユーザー情報を渡す方法は以下の2通りです。
- ユーザーIDを直接渡す
- ユーザートークンとして渡す
後者は、アプリケーションがユーザー認証で利用する認証基盤からトークンを受け取って、KendraのAPI/SDKのパラメーターとして渡します。
トークンを使う利点としては、トークンの検証をKendraにオフロードすることができるため、シンプルなコード記述かつ安全にアクセス制御を行うことができる点です。
参考情報: Kendraにおけるアクセス権限によるフィルタリング (前述したページの「アクセス制御 (Access Control)」の節を参照
おわりに
こうやって比較してみると、「Kendra」と「Bedrock Knowledge Bases」のどちらか一方が明らかに優れているということはなく、一長一短であることが分かります。
Kendraは豊富なデータソースコネクタが用意されていることが魅力ですし、Bedrock Knowledge Basesは次々に新機能が追加されることで使い勝手や検索精度が向上している点が注目されます。
生成AIの分野は今まさに日進月歩で進化していますので、今日の比較結果が、明日には変わっている可能性も十分にあります。
本記事は、BedrockやKendraのサービスアップデートに追随して今後も可能な限り最新化していきたいと考えています。
時々チェックしてもらえると嬉しいです。



